Análise 1st e 2nd level
Observações: Movimentação de corpo rígido:
Neste caso,
Em event-related, além da condição convoluída pela HRF, inclui também suas derivadas.
Para mapas de ativação de um indivíduo - 1st level
Se quiser sofisticar a análise com mais acurácia, realizamos os ajustes:
A adição de Kernels de Volterra:
- Além disso, trabalha-se com a autocorrelação dos resíduos. Seja o modelo
neste caso, supondo:
3.1 Pre-whitening: Aplicação de modelo autoregressivo 3.2 Estimação não-paramétrica e semi-paramétrica: Descobrir independência dos resíduos 3.3 Pre-coloring (AR) - Força os resíduos a ter a dependência desejada/conhecida que seja compatível com o modelo estatístico.
Análise de fMRI:
Um conjunto de dados fMRI, pode ser visto como um conjunto de elementos cubóides (isto é, voxels) de dimensão variável, cada qual explicados por uma série temporal associada de tantos pontos de tempo quanto os volumes adquiridos por sessão.
O objetivo de uma análise estatística (convencional) é determinar quais voxels têm um curso de tempo que se correlaciona com algum padrão conhecido de estimulação ou manipulação experimental. O primeiro passo na análise de dados de ressonância magnética funcional é aplicar uma série de transformações de “pré-processamento” com o objetivo de corrigir vários artefatos potenciais introduzidos na aquisição de dados. Cada transformação pode ser aplicada conforme necessário, dependendo do projeto experimental específico ou protocolo de aquisição. As etapas mais típicas incluem o ajuste de diferenças no tempo de aquisição de fatias de imagem individuais, correção do movimento do assunto, distorção dos dados de indivíduos individuais em um espaço comum (“normalização”) e suavização temporal e espacial (ver Jezzard et al., 2002). Após o pré-processamento, a análise de dados é geralmente realizada em duas etapas: uma análise de primeiro nível separada dos dados de cada indivíduo, seguida de uma análise de segundo nível na qual os resultados de vários assuntos são combinados.
As etapas de: * coleta de dados * pré-processamento * 1st level * e/ou 2nd level
Onde as análises são feitas em dois tipos:
- 1st level: Comparação entre ativação em condições no mesmo indivíduo
- 2nd level: Comparação entre condições em um grupo OU comparação entre grupos de indivíduos
Análise primeiro nível
O objetivo da análise estatística de primeiro nível é determinar o quão grande é a contribuição de cada variável preditora
Seja no primeiro nível a implementação do GLM:
onde,
A abordagem padrão para a análise de fMRI é ajustar o mesmo modelo de forma independente ao tempo de cada voxel. A covariância espacial entre voxels vizinhos é, portanto, tipicamente ignorada no estágio de ajuste do modelo. A presença de mais variáveis de resposta (isto é, voxels) do que observações (ou seja, volumes), juntamente com o objetivo de fazer afirmações topograficamente específicas sobre a atividade BOLD, tem tradicionalmente motivado essa abordagem “massiva-univariada”.
Análise de grupo - 2nd level:
As análises 2nd level se dividem em fixed effects (conclusões nos indivíduos que participaram do estudo) ou mixed effects/random para conclusões de onde os indivíduos foram amostrados. Em mixed effects, utiliza-se um grupo para amostrar um comportamento de uma população.
Na análise de grupo, podemos aplicar diversos testes de hipóteses, como teste
Exemplo: Suponha que para um voxel X, Y, Z temos os
Para N-indivíduos, terei N cérebros para analisar. Para cada indivíduo tenho um
Teste para um grupo:
Para testar se esse
e
Isso é equivalente a um teste T para uma amostra.
PRIMEIRO método: Comparando dois grupos:
Por exemplo sejam as matrizes:
e pacientes:
O modelo de GLM utilizado é:
e:
Considerando a base a qual os 37 primeiros indivíduos são controles saudáveis e os demais são pacientes com Parkinson.
Implementando no R:
#Leitura de biblioteca
require(RNifti)## Carregando pacotes exigidos: RNifti#Leitura dos dados
betas = readNifti("./data/grupo37C-P.nii")
dim(betas)## [1] 45 54 45 92# imagem axial do décimo individuo:
#imagem axial (z=20) do decimo individuo na fatia 20
image(betas[,, 20, 10])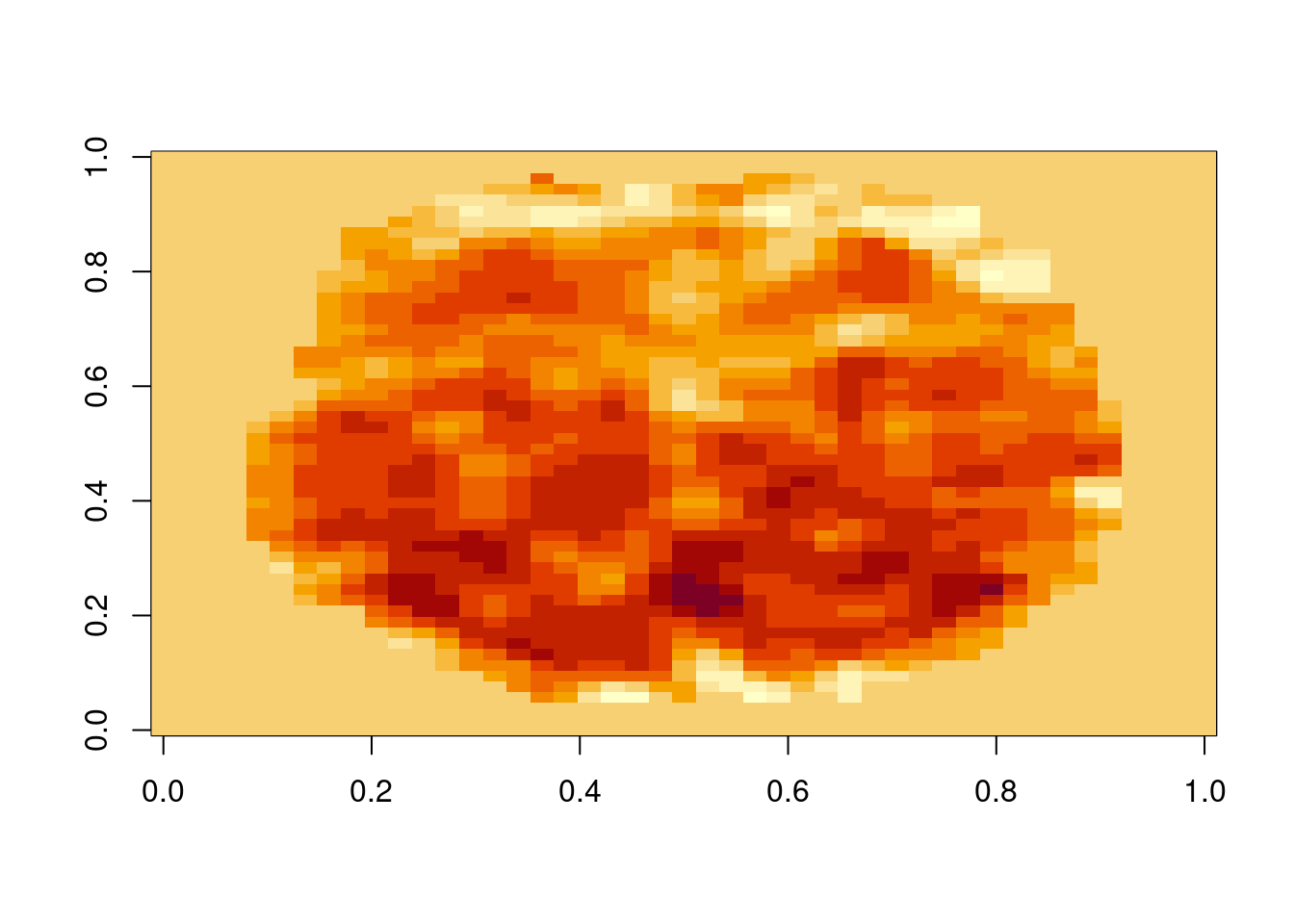
Para um único voxel 20, 20, 20:
Y = betas[20, 20, 20,]
X = matrix(0, 92, 2)
# Como 1: 37 são controle e do 38:92 são pacientes:
# Variável dummy para controles
X[1:37, 1] = 1
# Variável dummy para pacientes:
X[38:92, 2] = 1Ajustando o modelo - GLM:
#Ajustar o GLM
#o -1 na formula serve para tirar o intercepto
modelo = lm(Y~-1+X[, 1] + X[, 2])
summary(modelo)##
## Call:
## lm(formula = Y ~ -1 + X[, 1] + X[, 2])
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.50669 -0.15868 -0.03905 0.09441 1.15112
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## X[, 1] 0.48435 0.04685 10.34 <2e-16 ***
## X[, 2] 0.44014 0.03843 11.45 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.285 on 90 degrees of freedom
## Multiple R-squared: 0.7256, Adjusted R-squared: 0.7195
## F-statistic: 119 on 2 and 90 DF, p-value: < 2.2e-16Se olhar o
Analisando o teste de hipóteses e a ativação dos respectivos controles. Para ativação
Para entender se o controle ativa MAIS que o de pacientes:
Outro método: Grupos de referência
Para controles:
Para pacientes:
Neste caso:
Implementando para o mesmo voxel 20,20,20:
### METODO GRUPO DE REFERENCIA
#Neste caso sera o controle
#Observacao: os 37 primeiros indiv
#sao controles saudáveis e os demais
#sao pacientes com Parkinson
#GLM
Y = betas[20, 20, 20,]
X = matrix(0, 92, 2)
#Intercepto
X[, 1] = 1
#Variavel dummy para Pacientes
X[38:92, 2] = 1
#Ajustar o GLM
modelo = lm(Y~X[, 2])
summary(modelo)##
## Call:
## lm(formula = Y ~ X[, 2])
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.50669 -0.15868 -0.03905 0.09441 1.15112
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.48435 0.04685 10.34 <2e-16 ***
## X[, 2] -0.04421 0.06060 -0.73 0.468
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.285 on 90 degrees of freedom
## Multiple R-squared: 0.00588, Adjusted R-squared: -0.005166
## F-statistic: 0.5323 on 1 and 90 DF, p-value: 0.4675Analisando especificamente para esse voxel, como
Para análise dos mapas, analisamos mais o t-valor.
Fazendo a varredura para todos os voxeis intracranianos (análise de grupo de referência):
#GLM em todos os voxels intracranianos
MAPAT = array(0, c(45, 54, 45, 1))
for(xi in 1:45){
for(yi in 1:54){
for(zi in 1:45){
if(betas[xi, yi, zi, 1] != 0){
Y = betas[xi, yi, zi, ]
X = matrix(0, 92, 2)
#Intercepto
X[, 1] = 1
#Variavel dummy para Pacientes
X[38:92, 2] = 1
#Ajustar o GLM
modelo = lm(Y~X[, 2])
#Estatistica T do paciente vs controle
MAPAT[xi, yi, zi, 1] = summary(modelo)$coef[2, 3]
}#fecha if
}}}#fecha o for do xi,yi,zi
#Salva os mapas em arquivos no formato Analyze (IMG/HDR)
writeNifti(MAPAT,
"./data/MapaControlevsPaciente.nii.gz",
datatype="float")