Controle de qualidade
O número de tentativas necessárias para obter um ERP depende de vários fatores, sendo o mais importante a “relação sinal-ruído” (Signal to Noise Ratio), ou seja, o tamanho relativo do sinal (o ERP) em relação ao tamanho do ruído. Em experimentos cognitivos, 30 a 50 apresentações de estímulo são normalmente necessárias para se obter um ERP médio bom e limpo.
Identificação de épocas (períodos dos estímulos) num experimento. O número de épocas (trials) aumenta a SNR.
O código implementado abaixo foram calculados os ERPs associados aos dois tipos de estímulos (raros e frequentes) de um experimento. O sinal foi corrigido pela média do baseline, com a média de várias repetições para remoção de ruídos existentes.
#Leitura de dados
sinais=read.table("./data/OlhosFechados.txt",header=FALSE)
#Nome dos canais
nomescanais=scan("./data/NOMEScanais.txt",what="string")
dim(sinais)## [1] 45315 32nomescanais## [1] "Fp1" "Fp2" "F7" "F3" "Fz" "F4" "F8" "FC5" "FC1" "FC2"
## [11] "FC6" "T7" "C3" "Cz" "C4" "T8" "TP9" "CP5" "CP1" "CP2"
## [21] "CP6" "TP10" "P7" "P3" "Pz" "P4" "P8" "PO9" "O1" "Oz"
## [31] "O2" "PO10"Para saber o período de aquisição dos dados, basta dividir o número de linhas por 32:
# Considerando taxa de amostragem e convertendo pra minutos:
45315/(200*60)## [1] 3.77625# Conteúdo do vetor do trigger:
ts.plot(sinais)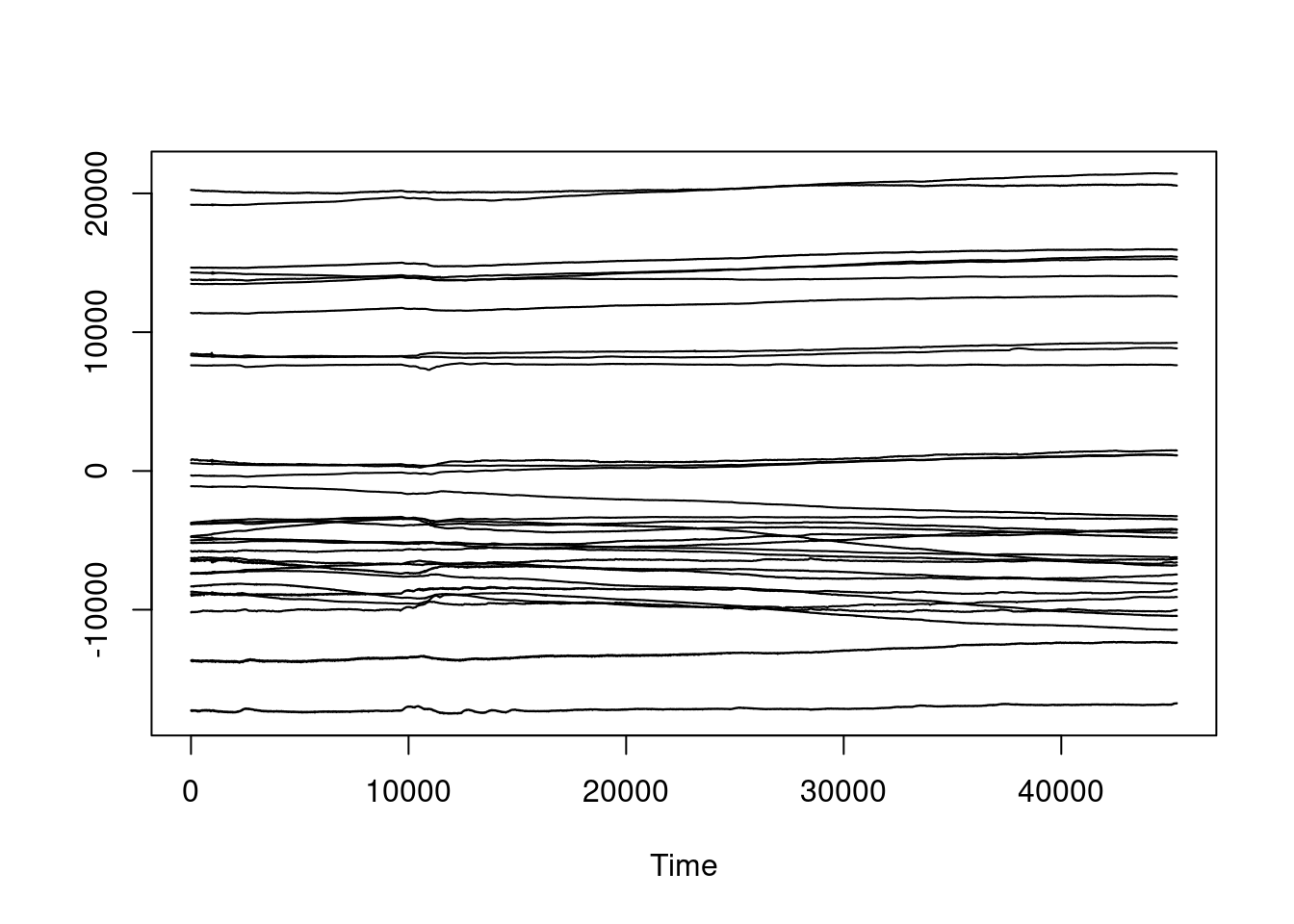
Para definição das épocas dos eventos (intervalos dos trials), precisamos identificar as amplitudes dos intervalos e assinalar na matriz os intervalos de tempo entre os eventos:
Comandos importantes:
round(): arredondamento matemático
floor(): arredondamento para baixo
ceiling(): arredondamento para cima
# Análisando uma época de 5s numa taxa de amostragem de 200hz:
# Considerando o tamanho de 5s, seria:
# TAM = seg * HZ = 5 * 200
HZ = 200 # taxa de amostragem considerada:
TamSegundos=5 # Numero de segundos do trial:
TAM = TamSegundos*HZ
Nepocas = floor(nrow(sinais)/TAM)
Ncanais = ncol(sinais)
# Inicializar a matriz com as amplitudes de cada epoca para cada canal:
#Inicializar a matriz com as amplitudes de cada epoca para cada canal
AMPLITUDE= matrix(0, Nepocas, Ncanais)
for(canal in 1:Ncanais){
for(epoca in 1:Nepocas){
#Casela de inicio da epoca
INICIO=(epoca-1)*TAM+1
#Casela de fim da epoca
FIM=epoca*TAM
#Calculo de amplitude
AMPLITUDE[epoca,canal]=max(sinais[INICIO:FIM,canal])- min(sinais[INICIO:FIM,canal])
}#for da epoca
}#for dos canaisPara analisar os dados da amplitude, podemos ver a distribuição no histograma abaixo:
#Analisar a distribuicao das amplitudes
hist(c(AMPLITUDE))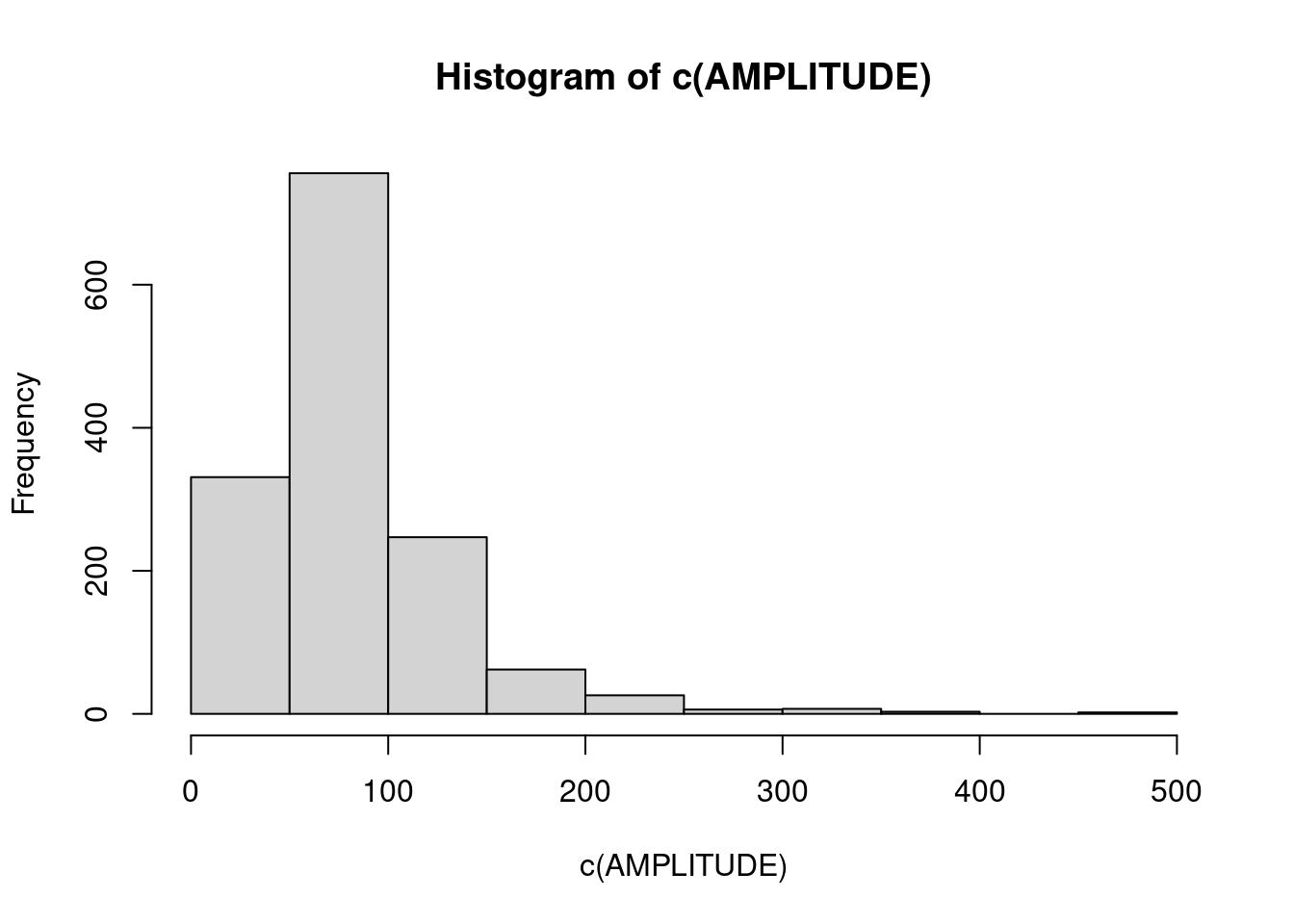
Limitando um pouco a visualização, no caso em 150:
LIMIAR=150 #escolhido analisando o histogramaCriando uma matriz de controle de qualidade de dimensão idêntica ao da matriz AMPLITUDE. O ZERO corresponde a épocas sem problemas e UM são as épocas onde a amplitude foi maior que um limiar:
CQ = matrix(0, Nepocas, Ncanais)
CQ[which(AMPLITUDE>LIMIAR)]=1Para identificar os CANAIS mais problemáticos e realizar a contagem das épocas descartadas em cada canal:
colSums(CQ)## [1] 8 2 4 1 1 0 0 2 0 0 0 11 6 0 1 8 10 0 0 1 1 9 4 0 1
## [26] 3 9 10 1 3 7 3Unindo as colunas dos canais com as épocas descartadas:
cbind(nomescanais,colSums(CQ))## nomescanais
## [1,] "Fp1" "8"
## [2,] "Fp2" "2"
## [3,] "F7" "4"
## [4,] "F3" "1"
## [5,] "Fz" "1"
## [6,] "F4" "0"
## [7,] "F8" "0"
## [8,] "FC5" "2"
## [9,] "FC1" "0"
## [10,] "FC2" "0"
## [11,] "FC6" "0"
## [12,] "T7" "11"
## [13,] "C3" "6"
## [14,] "Cz" "0"
## [15,] "C4" "1"
## [16,] "T8" "8"
## [17,] "TP9" "10"
## [18,] "CP5" "0"
## [19,] "CP1" "0"
## [20,] "CP2" "1"
## [21,] "CP6" "1"
## [22,] "TP10" "9"
## [23,] "P7" "4"
## [24,] "P3" "0"
## [25,] "Pz" "1"
## [26,] "P4" "3"
## [27,] "P8" "9"
## [28,] "PO9" "10"
## [29,] "O1" "1"
## [30,] "Oz" "3"
## [31,] "O2" "7"
## [32,] "PO10" "3"Agora identificando as ÉPOCAS mais problemáticas e verificar as épocas com problemas em mais de um canal:
rowSums(CQ)## [1] 11 7 9 5 2 4 2 2 2 4 15 15 4 3 2 1 0 0 0 0 0 0 0 0 0
## [26] 1 3 0 3 1 1 0 2 1 2 0 1 2 0 0 1 0 0 0 0Olhando um canal específico (ex: Fp1) na época 11:
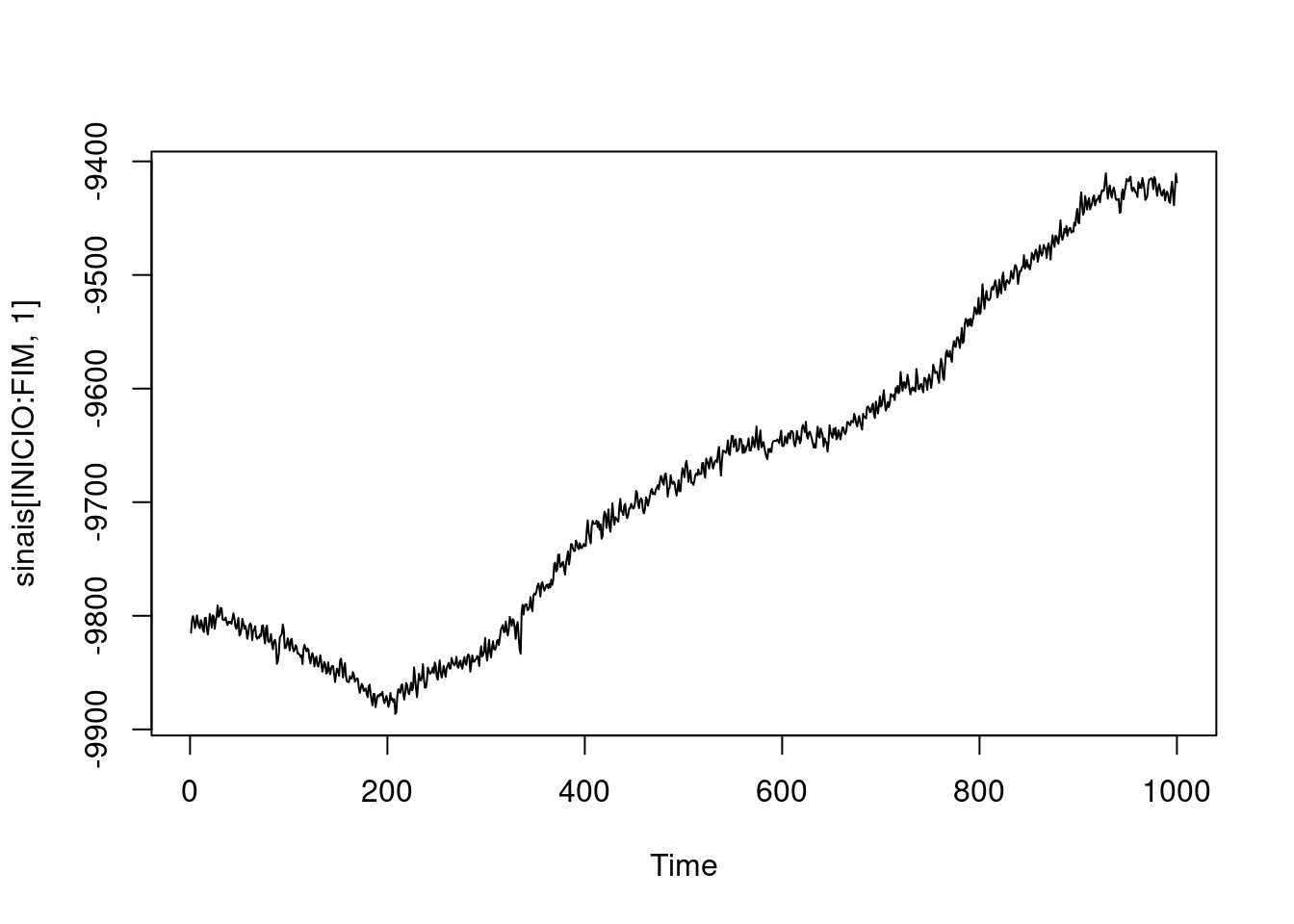
epoca=11
INICIO=(epoca-1)*TAM+1
FIM=epoca*TAM
ts.plot(sinais[INICIO:FIM,1])